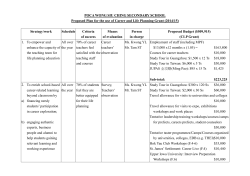
12. Recovery
Study Meeting
M1 Yuuki Horita
2004/5/14
Contents
Introduction
Recovery
Checkpointing
Difficulty of Checkpointing
Synchronous checkpointing / recovery
(Asynchronous checkpointing / recovery)
Introduction
Long computation in distributed environments
High failure rate
Host failure (a lot of hosts)
Network failure
One failure may disturb entire computation
⇒ Need to start it again from the beginning
High cost
Why don’t we utilize the previous computation?
Recovery
Recovery is not easy
Suppose that a parallel computation is running in
distributed resources…
1
7
8
1
7
8
1
7
1
7
for(i=0; i<MAXITER; i++){
• need to save process states periodically
local_compute();
// compute at each host
• usually other processes have to restore to
previous state
global_state_exchange();
// communicate with neighbors
• overhead
}
Recovery
Back/Forward Error Recovery
Forward-error recovery
Only when it is possible to remove errors
Enable processes to move forward
Ex) Redundancy, vote
Backward-error recovery
General
Restore to a previous error-free state
Ex) Checkpoint
Backward-error recovery
operational-based approach
Record all modifications of a process’ state
state-based approach
Record complete state at certain point
Recovery
Forward-error
Backward-error
operational-based
state-based
State-based approach
Terminology
checkpointing
the process of saving state
checkpoint
the recovery point at which checkpointing occurs
rolling back
the process of restoring a process to a prior-state
Checkpointing
Problem of naïve checkpointing
Orphan Messages and the Domino
Effect
Orphan message :
a message that make an inconsistent state
Domino Effect :
what a single rolling back induce other rolling back
Lost Messages
Livelocks
Orphan message and Domino Effect
X
x1
x2
x3
[
[
[
Y has not sent yet,
but X has received.
y1
Y
y2
[
[
: Orphan message
Roll back
Z
z1
z2
[
[
: Domino Effect
Lost messages
X
x1
x2
x3
[
[
[
X has sent, but Y
cannot receive forever
y1
Y
y2
[
[
: Lost message
Roll back
Z
z1
z2
[
[
Livelocks
x1
X
[
n1
y1
Y
[
m2
m1
n2
n1
Consistency of Checkpoint
Strongly consistent set of checkpoints
no messages penetrating the set
Consistent set of checkpoints
no messages penetrating the set backward
x1
x2
[
[
y1
need to deal with
lost messages
y2
[
[
Strongly consistent
z1
[
consistent
z2
[
Checkpoint/Recovery Algorithm
Synchronous
with global synchronization at checkpointing
Asynchronous
without global synchronization at checkpointing
Preliminary (Assumption)
~Synchronous Checkpoint~
Goal
To make a consistent global checkpoint
Assumptions
Communication channels are FIFO
No partition of the network
End-to-end protocols cope with message loss due to
rollback recovery and communication failure
No failure during the execution of the algorithm
Preliminary (Two types of checkpoint)
~Synchronous Checkpoint~
tentative checkpoint :
a temporary checkpoint
a candidate for permanent checkpoint
permanent checkpoint :
a local checkpoint at a process
a part of a consistent global checkpoint
Checkpoint Algorithm
~Synchronous Checkpoint~
Algorithm
1.
2.
3.
4.
5.
6.
an initiating process (a single process that invokes this algorithm) takes
a tentative checkpoint
it requests all the processes to take tentative checkpoints
it waits for receiving from all the processes whether taking a tentative
checkpoint has been succeeded
if it learns all the processes has succeeded, it decides all tentative
checkpoints should be made permanent; otherwise, should be
discarded.
it informs all the processes of the decision
The processes that receive the decision act accordingly
Supplement
Once a process has taken a tentative checkpoint, it shouldn’t send
messages until it is informed of initiator’s decision.
Diagram of Checkpoint Algorithm
~Synchronous Checkpoint~
Tentative
checkpoint
Initiator
[
decide to commit
|
request to
take a
tentative
checkpoint
[
[
consistent global checkpoint
[
|
|
OK
permanent checkpoint
[
[
Unnecessary checkpoint
consistent global checkpoint
Optimized Algorithm
~Synchronous Checkpoint~
Each message is labeled by order of sending
Labeling Scheme
X
[
x3
x2
⊥ : smallest label
y1
y2
т : largest label
[
Y
y2
last_label_rcvdX[Y] :
the last message that X received from Y after X has taken its last
permanent or tentative checkpoint. if not exists, ⊥is in it.
first_label_sentX[Y] : x2
the first message that X sent to Y after X took its last permanent or
tentative checkpoint . if not exists, ⊥is in it.
ckpt_cohortX :
the set of all processes that may have to take checkpoints when X
decides to take a checkpoint.
Checkpoint request need to be sent to only the processes
included in ckpt_cohort
Optimized Algorithm
~Synchronous Checkpoint~
ckpt_cohortX : { Y | last_label_rcvdX[Y] > ⊥ }
Y takes a tentative checkpoint only if
last_label_rcvdX[Y] >= first_label_sentY[X] > ⊥
X
Y
last_label_rcvdX[Y]
[
[
first_label_sentY[X]
Optimized Algorithm
~Synchronous Checkpoint~
Algorithm
1.
2.
3.
4.
5.
6.
7.
an initiating process takes a tentative checkpoint
it requests p ∈ ckpt_cohort to take tentative checkpoints ( this
message includes last_label_rcvd[reciever] of sender )
if the processes that receive the request need to take a
checkpoint, they do the same as 1.2.; otherwise, return OK
messages.
they wait for receiving OK from all of p ∈ ckpt_cohort
if the initiator learns all the processes have succeeded, it
decides all tentative checkpoints should be made permanent;
otherwise, should be discarded.
it informs p ∈ ckpt_cohort of the decision
The processes that receive the decision act accordingly
Diagram of Optimized Algorithm
~Synchronous Checkpoint~
Tentative
Permanent
checkpoint
[
A
ab1
ba1
ba2
[
bd1
ca2
2 >= 1 > 0
OK
ac2
[
dc1
2 >= 0 > 0
[|
cb2
cb1
C
D
[|
ac1
B
decide to commit
[|
cd1
dc2
[
ckpt_cohortX : { Y | last_label_rcvdX[Y] > ⊥ }
last_label_rcvdX[Y] >= first_label_sentY[X] > ⊥
2 >= 2 > 0
Correctness
~Synchronous Checkpoint~
A set of permanent checkpoints taken by this
algorithm is consistent
No process sends messages after taking a
tentative checkpoint until the receipt of the
decision
New checkpoints include no message from the
processes that don’t take a checkpoint
The set of tentative checkpoints is fully either
made to permanent checkpoints or discarded.
Recovery Algorithm
~Synchronous Recovery~
Labeling Scheme
⊥ : smallest label
т : largest label
last_label_rcvdX[Y] :
the last message that X received from Y after X has taken its
last permanent or tentative checkpoint. If not exists, ⊥is in it.
first_label_sentX[Y] :
the first message that X sent to Y after X took its last permanent
or tentative checkpoint . If not exists, ⊥is in it.
roll_cohortX :
the set of all processes that may have to roll back to the latest
checkpoint when process X rolls back.
last_label_sentX[Y] :
the last message that X sent to Y before X takes its latest
permanent checkpoint. If not exist, т is in it.
Recovery Algorithm
~Synchronous Recovery~
roll_cohortX = { Y | X can send messages to Y }
Y will restart from the permanent checkpoint only if
last_label_rcvdY[X] > last_label_sentX[Y]
Recovery Algorithm
~Synchronous Recovery~
Algorithm
1.
2.
3.
4.
5.
6.
an initiator requests p ∈ roll_cohort to prepare to rollback
( this message includes last_label_sent[reciever] of
sender )
if the processes that receive the request need to rollback,
they do the same as 1.; otherwise, return OK message.
they wait for receiving OK from all of p ∈ ckpt_cohort.
if the initiator learns p ∈ roll_cohort have succeeded, it
decides to rollback; otherwise, not to rollback.
it informs p ∈ roll_cohort of the decision
the processes that receive the decision act accordingly
Diagram of Synchronous Recovery
decide to
roll back
[
A
ab1
ba1
ac1
OK
[
B
bd1
cb2
cb1
ac2
dc1
2
0>1
request to
roll back
[
C
D
ba2
2>1
dc1
dc2
[
0 >т
roll_cohortX = { Y | X can send messages to Y }
last_label_rcvdY[X] > last_label_sentX[Y]
Drawbacks of Synchronous Approach
Additional messages are exchanged
Synchronization delay
An unnecessary extra load on the system if
failure rarely occurs
Asynchronous Checkpoint
Characteristic
Each process takes checkpoints independently
No guarantee that a set of local checkpoints is
consistent
A recovery algorithm has to search consistent set
of checkpoints
No additional message
No synchronization delay
Lighter load during normal excution
Preliminary (Assumptions)
~Asynchronous Checkpoint / Recovery~
Goal
To find the latest consistent set of checkpoints
Assumptions
Communication channels are FIFO
Communication channels are reliable
The underlying computation is event-driven
Preliminary (Two types of log)
~Asynchronous Checkpoint / Recovery~
save an event on the memory at receipt of
messages (volatile log)
volatile log periodically flushed to the disk
(stable log) ⇔ checkpoint
volatile log :
quick access
lost if the corresponding processor fails
stable log :
slow access
not lost even if processors fail
Preliminary (Definition)
~Asynchronous Checkpoint / Recovery~
Definition
CkPti : the checkpoint (stable log) that i rolled back to when
failure occurs
RCVDi←j (CkPti / e ) :
the number of messages received by processor i from processor
j, per the information stored in the checkpoint CkPti or event e.
SENTi→j(CkPti / e ) :
the number of messages sent by processor i to processor j, per
the information stored in the checkpoint CkPti or event e
Recovery Algorithm
~Asynchronous Checkpoint / Recovery~
Algorithm
1.
2.
3.
4.
5.
6.
When one process crashes, it recovers to the latest
checkpoint CkPt.
It broadcasts the message that it had failed. Others
receive this message, and rollback to the latest event.
Each process sends SENT(CkPt) to neighboring
processes
Each process waits for SENT(CkPt) messages from every
neighbor
On receiving SENTj→i(CkPtj) from j, if i notices RCVDi←j
(CkPti) > SENTj→i(CkPtj), it rolls back to the event e such
that RCVDi←j (e) = SENTj→i(e),
repeat 3,4,and 5 N times (N is the number of processes)
Asynchronous Recovery
X:Y
X
Ex0
x1
[
Ex1
Ex2
Ex3
3 <= 2
2
(Y,2)
Ey0
Ey1
Ey2
y1
[
Y
Z
[
Ez1
0 <= 0
(X,2) (Z,0)
Y:X
Ey3
1 <= 2
Y:Z
1 <= 1
(X,0)
(Y,1)
Ez0
X:Z
(Z,1)
Ez2
z1
RCVDi←j (CkPti) <= SENTj→i(CkPtj)
Z:X
0 <= 0
Z:Y
1
2 <= 1
© Copyright 2026 ExpyDoc